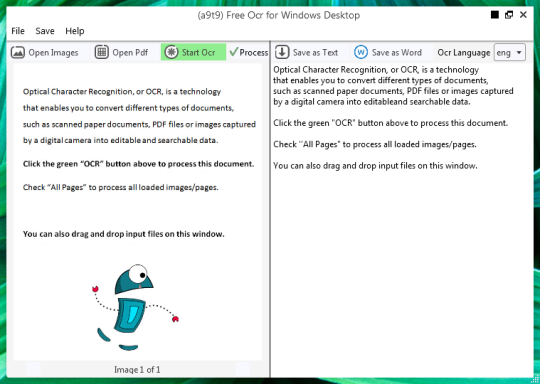
Vapaa OCR poimia tekstiä kuvatiedostoja ja PDF kohteita. Graafinen käyttöliittymä (GUI) Tesseract OCR moottori.
Sovellus on helppo asentaa, ja mikä tärkeintä, vapaasti käyttää, avoimen lähdekoodin ja 100% vapaa mainos- ja vakoiluohjelmista.
Voit avata kuvan tai PDF-tiedoston. Sisältö lähdetiedoston näkyy vasemmassa ikkunassa. Jos asiakirja enemmän kuin yhden sivun, tai jos avasit monisivuisia asiakirjoja, käytä nuolia alareunassa vaihtaa niiden välillä,
Voit aloittaa OCR napsauttamalla vihreää OCR-painiketta, ja näet tuloksen toisella oikeassa ikkunassa. Lähtö teksti voidaan tallentaa tekstitiedostoksi tai Word-asiakirjaan.
Valitettavasti muuntaminen laatu ei ole niin suuri. Kulissien takana se käyttää Tesseract avoimen lähdekoodin OCR moottori. Laatu vaihtelee kielikohtaisesti - niin mene eteenpäin ja testata, jos se riittää tarpeisiisi.
Ohjelmistokehittäjille ja geeks: Vapaa OCR Windows Desktop työkalu on pohjimmiltaan graafinen käyttöliittymä etupään (GUI) Tesseract OCR moottori. Koko lähdekoodin on saatavilla (GPL lisenssi).
OCR moottori ohjelmisto tukee seuraavia OCR-kieli: Englanti, ranska, italia, saksa, espanja, Brasilian portugali ja hollanti. Alkaen versio 3 se voi tunnistaa arabia, bulgaria, katalaani, kiina (yksinkertaistettu ja perinteinen), kroatia, tšekki, tanska, Hollanti, Englanti, saksa (vakio ja Fraktur käsikirjoitus), kreikka, suomi, ranska, heprea, Hindi, unkari, indonesia, italia, japani, korea, latvia, liettua, Norja, Puola, Portugali, Romania, Venäjä, Serbia, Slovakki (vakio ja Fraktur käsikirjoitus), unkarin, viron, Tagalog, tamili, thai, turkki, ukraina ja Vietnam.
Kommentteja ei löytynyt