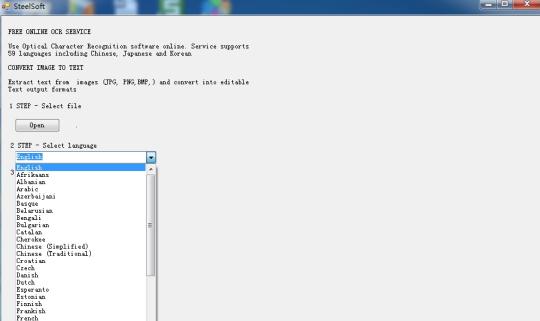
Tunnista teksti kuvia käyttämällä Tesseract OCR moottori perustuu pilvi teknologiaan.
Käytä Optical Character Recognition-ohjelmisto verkossa. Palvelu tukee 59 kielellä, mukaan lukien kiina, japani ja korea. Poimia tekstiä kuvia (JPG, PNG, BMP, TIF) ja muuntaa muokattavaksi tekstiksi Tulostusmuodot.
Se perustuu pilvi teknologiaan, ja hyvin kuuluisa OCR moottori (Tesseract OCR moottori), joten on vain satoja kilotavua, mutta se voi poimia tekstiä 59 kielellä, kuvista.
Se tukee useampia kieliä: bulgaria, katalaani, tšekki, tanska, Hollanti, Englanti, suomi, ranska, saksa, kreikka, unkari, indonesia, italia, latvia, liettua, Norja, Puola, Portugali, Romania, Venäjä, Serbia, slovakki, sloveeni , Espanja, Ruotsi, Tagalog, turkki, ukraina, Vietnam jne.
Mikä on uusi tässä julkaisussa:
Versio 5.0 sisältää UE parannuksia.

Kommentteja ei löytynyt